
Author: the owner of the establishment.
This seems to be a popular introduction to Capsule Networks. In Part I, on the “intuition” behind them, the author (not Geoffrey Hinton, although formatted the same as a quote from him immediately above) says:
Internal data representation of a convolutional neural network does not take into account important spatial hierarchies between simple and complex objects.
This is very simply not true. In fact, Sabour, Hinton and Frosst address this issue in their Dynamic Routing Between Capsules [pdf]:
Now that convolutional neural networks have become the dominant approach to object recognition, it makes sense to ask whether there are any exponential inefficiencies that may lead to their demise. A good candidate is the difficulty that convolutional nets have in generalizing to novel viewpoints. The ability to deal with translation is built in, but for the other dimensions of an affine transformation we have to chose between replicating feature detectors on a grid that grows exponentially with the number of dimensions, or increasing the size of the labelled training set in a similarly exponential way. Capsules (Hinton et al. [2011]) avoid these exponential inefficiencies…
This is fundamental, and I hope folks avoid the error in thinking that ConvNets can’t “take into account important spatial hierarchies between simple and complex objects”. That’s exactly what they do, but as models of how brains take into account these hierarchies under transformations, they are badly inefficient at doing so.
From Andrew Ng’s recent video on end-to-end deep learning. Really helps me make sense of being in Cognitive Science/Computer Science graduate programs ~1999-2006.
“One interesting sociological effect in AI is that as end-to-end deep learning started to work better, there were some researchers that had for example spent many years of their career designing individual steps of the pipeline. So there were some researchers in different disciplines not just in speech recognition. Maybe in computer vision, and other areas as well, that had spent a lot of time you know, written multiple papers, maybe even built a large part of their career, engineering features or engineering other pieces of the pipeline. And when end-to-end deep learning just took the last training set and learned the function mapping from x and y directly, really bypassing a lot of these intermediate steps, it was challenging for some disciplines to come around to accepting this alternative way of building AI systems. Because it really obsoleted in some cases, many years of research in some of the intermediate components. It turns out that one of the challenges of end-to-end deep learning is that you might need a lot of data before it works well. So for example, if you’re training on 3,000 hours of data to build a speech recognition system, then the traditional pipeline, the full traditional pipeline works really well. It’s only when you have a very large data set, you know one to say 10,000 hours of data, anything going up to maybe 100,000 hours of data that the end-to end-approach then suddenly starts to work really well. So when you have a smaller data set, the more traditional pipeline approach actually works just as well. Often works even better. And you need a large data set before the end-to-end approach really shines.”
This is a very good headline to be pushing these days:
Its source explains how Reuters attempts to turn the detection of fake news into a supervised learning problem.
News Tracer also must decide whether a tweet cluster is “news,” or merely a popular hashtag. To build the system, Reuters engineers took a set of output tweet clusters and checked whether the newsroom did in fact write a story about each event—or whether the reporters would have written a story, if they had known about it. In this way, they assembled a training set of newsworthy events. Engineers also monitored the Twitter accounts of respected journalists, and others like @BreakingNews, which tweets early alerts about verified stories. All this became training data for a machine-learning approach to newsworthiness. Reuters “taught” News Tracer what journalists want to see.
That’s how the labels are assigned.
Here’s how the features are assigned:
The system analyzes every tweet in real time—all 500 million or so each day. First it filters out spam and advertising. Then it finds similar tweets on the same topic, groups them into “clusters,” and assigns each a topic such as business, politics, or sports. Finally it uses natural language processing techniques to generate a readable summary of each cluster.
and
News Tracer assigns a credibility score based on the sorts of factors a human would look at, including the location and identity of the original poster, whether he or she is a verified user, how the tweet is propagating through the social network, and whether other people are confirming or denying the information. Crucially, Tracer checks tweets against an internal “knowledge base” of reliable sources. Here, human judgment combines with algorithmic intelligence: Reporters handpick trusted seed accounts, and the computer analyzes who they follow and retweet to find related accounts that might also be reliable.
Dr. David McCarty used to joke to me that people who didn’t understand the factive nature of “facts” wanted computers to detect them using logic. Of course, that’s impossible.
Machine learning yokes computers to the world. For this reason, the joke isn’t funny when it’s machine learning detecting facts. This is how “learning machines”, to use Turing’s term, contains the solution to the failures of logic-based AI. This is what Geoffrey Hinton was getting at in his short, pithy acceptance speech for the IEEE Maxwell Medal:
50 years ago, the fathers of artificial intelligence convinced everybody that logic was the key to intelligence. Somehow we had to get computers to do logical reasoning. The alternative approach, which they thought was crazy, was to forget logic and try and understand how networks of brain cells learn things. Curiously, two people who rejected the logic based approach to AI were Turing and Von Neumann. If either of them had lived I think things would have turned out differently… now neural networks are everywhere and the crazy approach is winning.
Categories
Is this what Phil was on about?

Source: “Technology and Courage” (warning, PDF) by Ivan Sutherland, April 1996, pg. 29. That last bit about what scientific progress is — what a gem. Anyone know where he got that from?
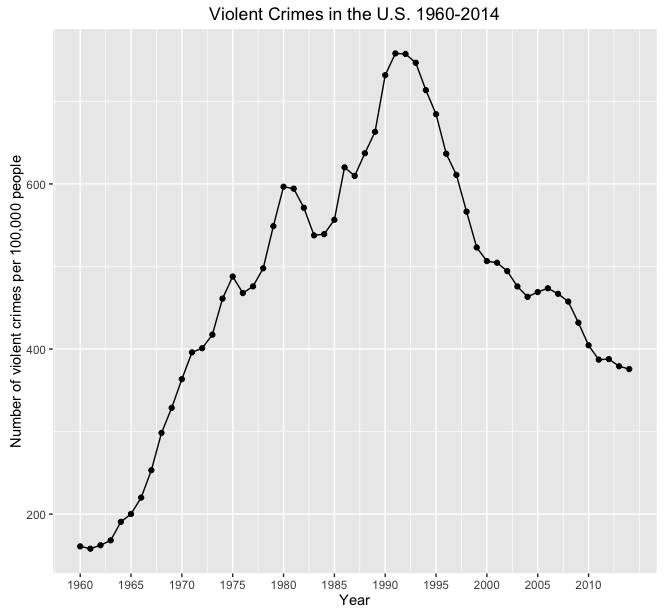
Consider the following terrible visualization:
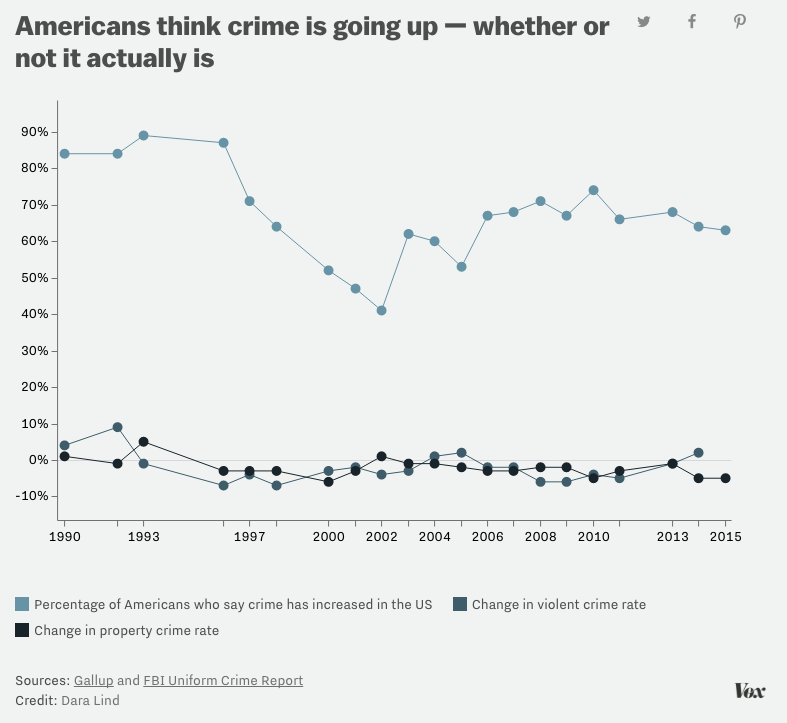
Here are some serious problems with the presentation of data here:
- Having a statistic hovering around at around 10 times the differences of the important numbers makes them look small and insignificant.
- One scale applies to percentage of the population and another to year over year change.
I received this from my University admin two days ago — the “reply” address for this email is not monitored.
I’ve written a short bit of python and given instructions for archiving myweb.dal.ca content — it’s up to you to supply URL(s) to the script.
Categories
New York Primary: Google Trends
Sharky Laguana, if that is your real name, you get at least two things wrong in your article about streaming music.
- It’s spelled “aficionados”;
- Your argument about inequity depends on facts you don’t have about distribution of choices.
We can do number 2 a couple of different ways.
Your Rdio spreadsheet example only works, with its difference between columns, on the premise that Brendan is the only person paying each of the artists for which the inequity is great.
Let’s do an example. Suppose that everyone, on average, has the same musical tastes, and listens to artists at the same rate. I know that’s not true — but if it were, then clearly there would be no difference between the Subscriber Share and Big Pool methods as you call them:
1/8x +1/8y = 1/8(x + y)
Your argument requires the premise that distribution of artists listened to is very different at different streaming levels. Do you know this? If so, how?
Finally, I find it funny that you think that these companies aren’t aware of the problem of stream falsification, and aren’t working on addressing it.