- Minsky and Papert’s Summer vision project (PDF)
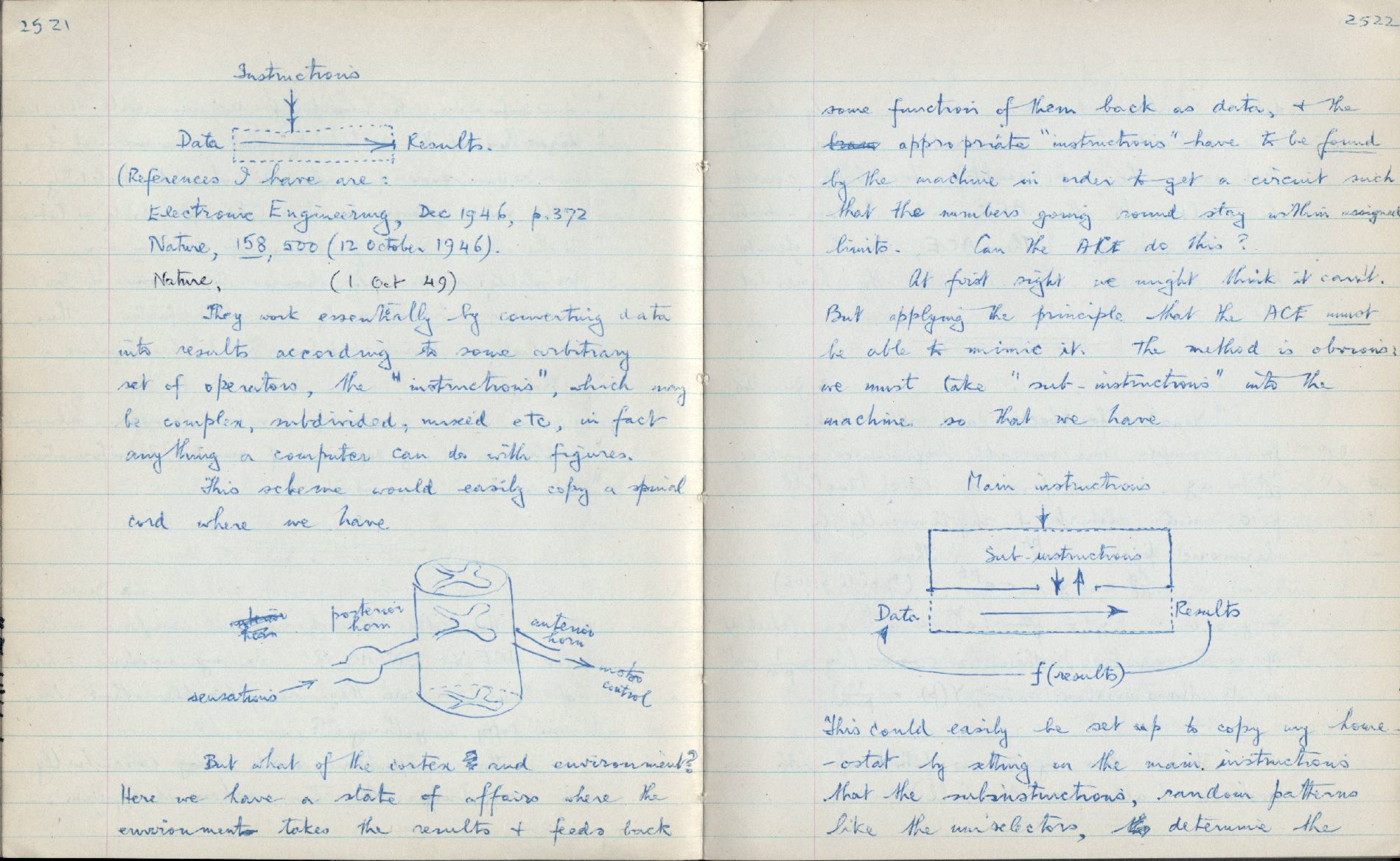
- Ashby notebooks, pages of interest (JPG):
- See also CSHPS slides, 2019
Category: Philosophy of Machine Learning
{kind=link}
{kind=link}
{kind=link}
The slides for my talk “The Return of Mind Design: Cognitive Science and the Turing/Ashby Debate”, with Erik Nelson, June 1, 2019 at the University of British Columbia are available here.
Slides located here.

From Andrew Ng’s recent video on end-to-end deep learning. Really helps me make sense of being in Cognitive Science/Computer Science graduate programs ~1999-2006.
“One interesting sociological effect in AI is that as end-to-end deep learning started to work better, there were some researchers that had for example spent many years of their career designing individual steps of the pipeline. So there were some researchers in different disciplines not just in speech recognition. Maybe in computer vision, and other areas as well, that had spent a lot of time you know, written multiple papers, maybe even built a large part of their career, engineering features or engineering other pieces of the pipeline. And when end-to-end deep learning just took the last training set and learned the function mapping from x and y directly, really bypassing a lot of these intermediate steps, it was challenging for some disciplines to come around to accepting this alternative way of building AI systems. Because it really obsoleted in some cases, many years of research in some of the intermediate components. It turns out that one of the challenges of end-to-end deep learning is that you might need a lot of data before it works well. So for example, if you’re training on 3,000 hours of data to build a speech recognition system, then the traditional pipeline, the full traditional pipeline works really well. It’s only when you have a very large data set, you know one to say 10,000 hours of data, anything going up to maybe 100,000 hours of data that the end-to end-approach then suddenly starts to work really well. So when you have a smaller data set, the more traditional pipeline approach actually works just as well. Often works even better. And you need a large data set before the end-to-end approach really shines.”